响应式系统的设计与实现 #11
Description
响应式数据与副作用函数
副作用函数也就是会产生副作用的函数,例如:
function effect () {
document.body.innerText = 'hello world'
}假设在一个副作用函数中读取了某个对象的属性:
const obj = { text: 'hello world' }
function effect () {
document.body.innerText = obj.text
}当obj.text的值发生变化时,我们希望副作用函数effect会重新执行,如果能实现这个目标,那么对象obj就是响应式数据。
响应式数据的基本实现
如何才能让obj变成响应式数据呢?通过观察我们发现两点线索:
- 当副作用函数effect执行时,会触发字段obj.text的
读取操作 - 当修改obj.text的值时,会触发字段obj.text的
设置操作
如果我们能拦截一个对象的读取和设置操作,事情就变得简单了。
当读取字段obj.text时,我们可以把副作用函数effect存储到一个“桶”里面
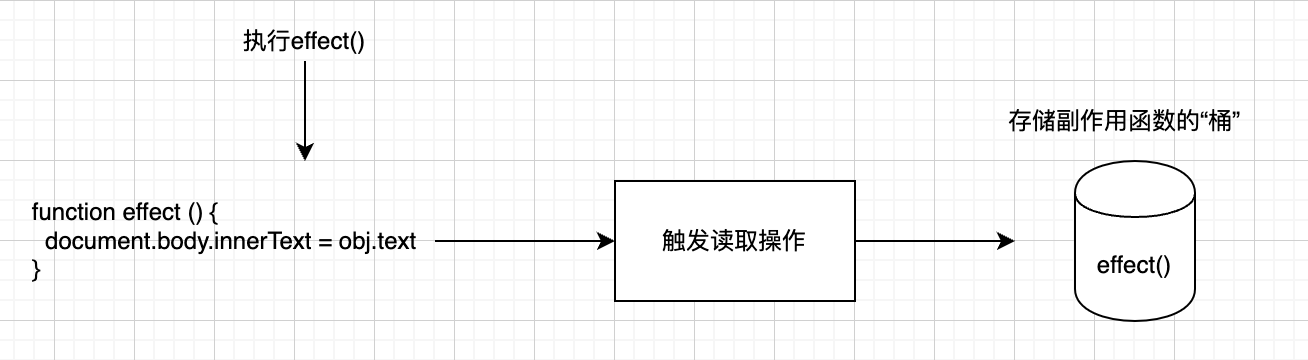
接着,当设置obj.text时,再把副作用函数从“桶”里取出并执行即可
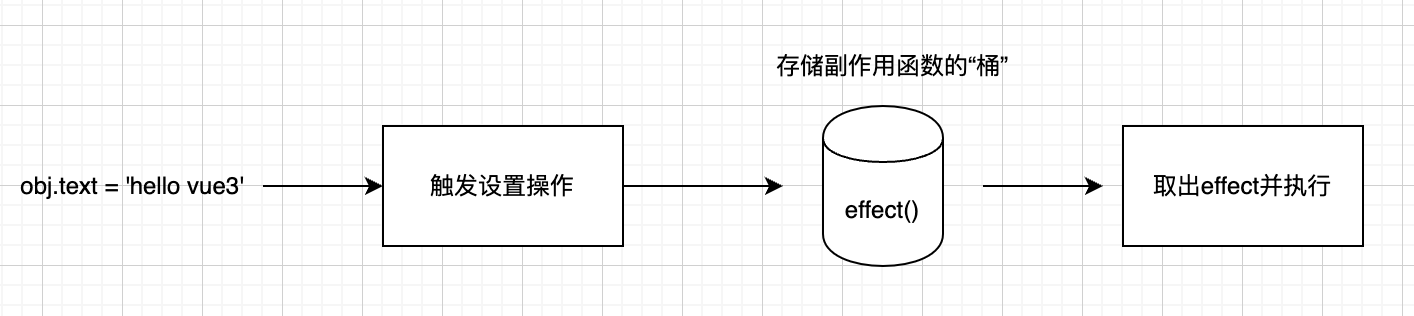
那么我们怎么才能拦截一个对象属性的读取和设置操作呢?在ES2015之前我们采用Object.defineProperty函数来实现,在ES2015之后,我们可以使用代理对象Proxy来实现:
// 存储对象的桶
const bucket = new Set()
// 原始数据
const data = { text: 'hello world' }
// 对原始数据的代理
const obj = new Proxy(data, {
// 拦截读取操作
get (target, key) {
// 将副作用函数effect添加到存储副作用函数的桶中
bucket.add(effect)
return target[key]
},
// 拦截设置操作
set (target, key, newVal) {
// 设置属性值
target[key] = newVal
// 将副作用函数从桶里取出并执行
bucket.forEach(fn => fn())
// 返回true代表设置操作成功
return true
}
})这时,我们更改data.text的值后,即可实现effect函数的调用
但是目前的实现存在很多缺陷,例如我们直接通过名字(effect)来获取副作用函数,这种硬编码方式很不灵活。副作用函数的名字应该可以任意的取,我们完全可以把副作用函数命名为myEffect,甚至是一个匿名函数,因此我们要想办法去掉这种硬编码的机制。
设计一个完整的响应式系统
首先我们需要提供一个用来注册副作用函数的机制:
// 用一个全局变量存储被注册的副作用函数
let activeEffect
const fn = () => {
document.body.innerText = obj.text
}
// effect函数用于注册副作用函数
function effect (fn) {
acticeEffect = fn
fn()
}所以当effect函数执行时,我们可以把匿名的副作用函数fn赋值给全局变量 activeEffect,接着执行fn,然后就触发了响应式数据obj.text的读取操作,进而触发代理对象Proxy的get拦截函数。
下一个问题是,当我们在obj上设置一个不存在的属性时:
obj.notExist = 'hello vue3'这个操作是在副作用函数fn之外进行的,但这时也会触发obj的设置操作,从而触发副作用函数的执行。导致该问题的根本原因是:没有在副作用函数与被操作的目标字段之间建立明确的联系。我们需要重新设计“桶”的数据结构。
如果用target来表示被代理的obj,用key来表示被操作的属性,用effectFn来表示被注册的副作用函数,那么会有以下关系:
target
|—— key1
|——effectFn1
|—— key2
|——effectFn2
我们可以用WeakMap代替Set作为“桶”的数据结构:
- WeakMap由target --> Map构成
- Map由 key --> Set构成
关系如图所示:
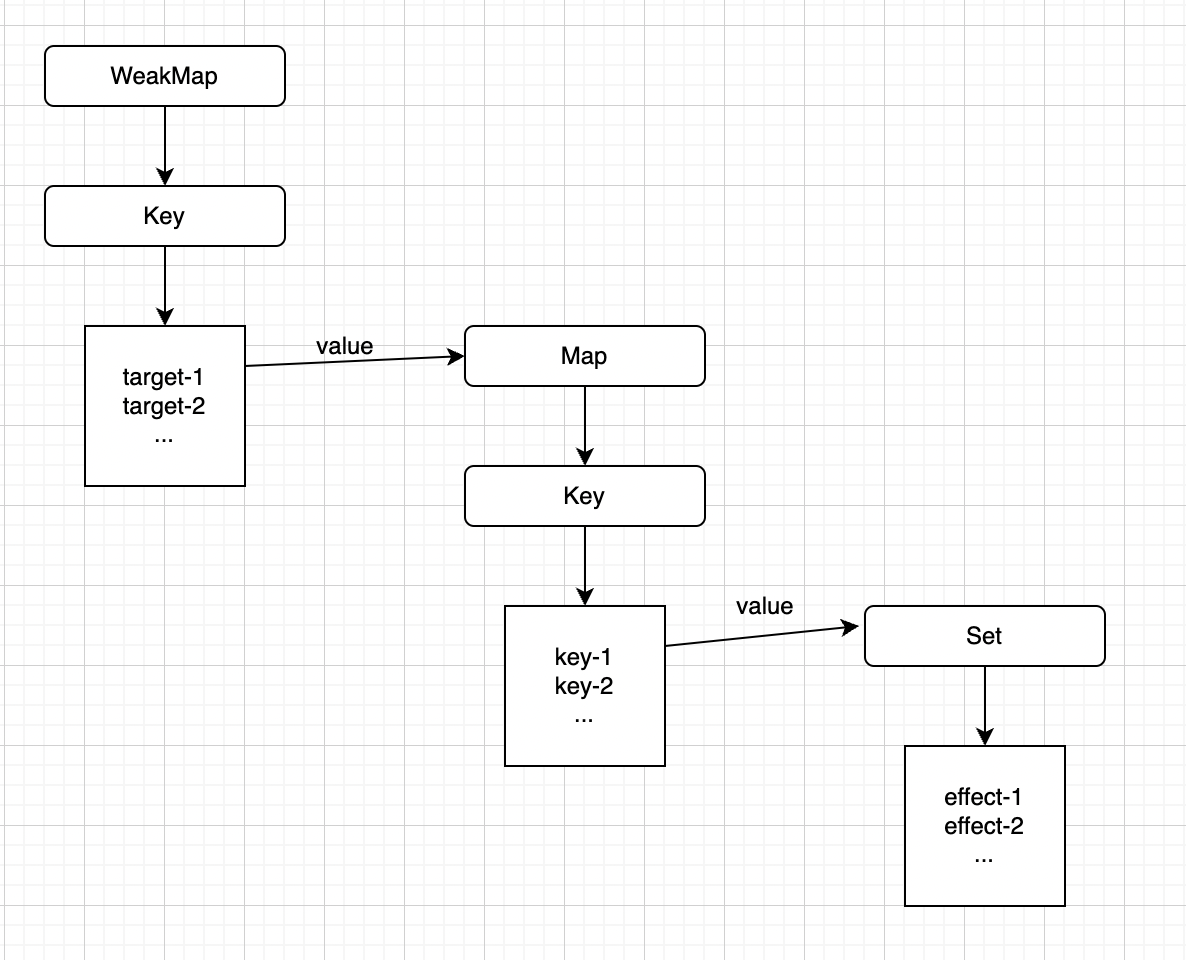
❓为何要使用WeakMap?
这涉及到垃圾回收机制,WeakMap的key是弱引用,它不影响垃圾回收器的工作,所以一旦表达式执行完毕,垃圾回收器就会将key从内存中移除。
所以WeakMap经常用于存储那些只有当key所引用的对象存在时(没有被回收)才有价值的信息,例如上面的场景中,如果target对象没有任何引用了,说明用户侧不再需要它了,这时垃圾回收器会完成回收任务。但如果使用Map,那么这个target将不会被回收,最终可能导致内存溢出。
初步实现:
const obj = new Proxy (data, {
// 拦截读取操作
get(target, key) {
// 将副作用函数activeEffect 添加到存储副作用函数的桶中
track(target, key)
return target[key]
},
// 拦截设置操作
set(target, key, newVal) {
//设置属性值
target[key] = newVal
// 把副作用函数从桶里取出并执行
trigger (target, key)
}
})
// 在get 拦截函数内调用 track 函数追踪变化
function track(target, key) {
// 没有activeEffect,直接 return
if (!activeEffect) return
let depsMap = bucket.get(target)
if (!depsMap) {
bucket.set(target, (depsMap = new Map()))
}
let deps = depsMap.get(key)
if (!deps) {
depsMap.set(key, (deps = new Set()))
}
deps.add(activeEffect)
}
// 在set 拦截函数内调用 trigger 函数触发变化
function trigger (target, key) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
effects && effects.forEach(fn => fn())
}当读取属性值时,我们直接在get拦截函数里编写把副作用函数收集到 “桶”里的这部分逻辑单独封装到一个 track 函数中,函数的名字叫 track 是为了表达追踪的含义。同样,我们也可以把触发副作用函数重新执行的逻辑封装到trigger函数中。
分支切换与cleanup
切换分支的定义:
const data = { ok: true, text: 'hello' }
const obj = new Proxy(data, { /* ... */ })
effect(function effectFn() {
document.body.innerText = obj.ok ? obj.text : 'not'
})当字段obj.ok的值发生变化时,代码执行的分支会跟着变化,这就是所谓的分支切换。
这时,副作用函数与响应式数据之间建立的联系如下:
data
|—— ok
|——effectFn
|—— text
|——effectFn
副作用函数 effectFn 分别被字段 data.ok 和字段 data.text 所对应的依赖集合收集
也就是说,当我们切换分支时,obj.ok = false,此时不会再读取 obj.text 的值,那么 obj.text 的值此时再变化后就不应该再继续执行 effectFn,我们需要及时清理遗留的副作用函数,以达到这个效果。
解决这个问题的思路是:每次副作用函数执行时,我们需要先把它从所有与之关联的依赖集合中删除,当副作用函数执行完毕后,会重新建立联系,但在新的联系中不会包含遗留的副作用函数。
要将一个副作用函数从所有关联的依赖集合中移除,就需要明确知道哪些依赖集合中包含它,因此我们需要重新设计副作用函数:
// 用一个全局变量存储被注册的副作用函数
let activeEffect
// effect函数用于注册副作用函数
function effect (fn) {
const effectFn = () => {
// 当 effectFn 执行时,将其设置为当前激活的副作用函数
activeEffect = effectFn
fn()
}
// activeEffect.deps 用来存储所有与该副作用函数相关联的依赖集合
effectFn.deps = []
effectFn()
}在 effect 内部我们定义了新的 effectFn 函数,并为其添加了 effectFn.deps 属性,该属性是一个数组,用来存储所有包含当前副作用函数的依赖集合。
那么 effectFn.deps 数组中的依赖集合是如何收集的呢?其实是在 track 函数中:
// 在get 拦截函数内调用 track 函数追踪变化
function track(target, key) {
// 没有activeEffect,直接 return
if (!activeEffect) return
let depsMap = bucket.get(target)
if (!depsMap) {
bucket.set(target, (depsMap = new Map()))
}
let deps = depsMap.get(key)
if (!deps) {
depsMap.set(key, (deps = new Set()))
}
// 把当前激活的副作用函数添加到依赖集合 deps 中
deps.add(activeEffect)
// deps 就是一个与当前副作用函数存在联系的依赖集合
// 将其添加到 activeEffect.deps 数组中
activeEffect.deps.push(deps) // 新增
}关系如图所示:
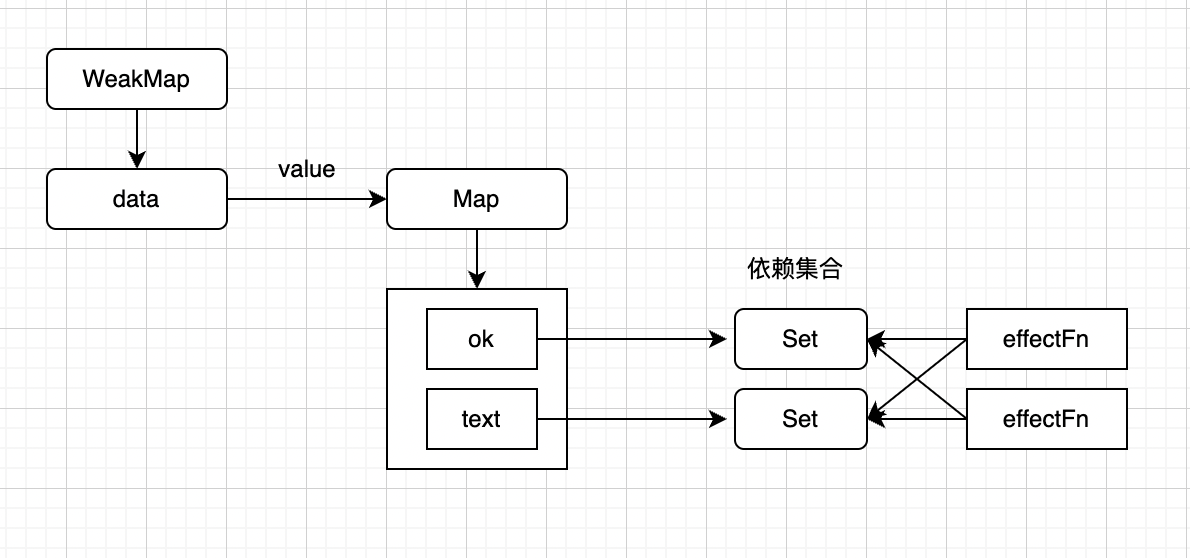
有了这个联系后,我们就可以在每次副作用函数执行时,根据 effectFn.deps 获取所有相关联的依赖集合,进而将副作用函数从依赖集合中移除:
// 用一个全局变量存储被注册的副作用函数
let activeEffect
// effect函数用于注册副作用函数
function effect (fn) {
const effectFn = () => {
cleanup(effectFn) // 新增
activeEffect = effectFn
fn()
}
// activeEffect.deps 用来存储所有与该副作用函数相关联的依赖集合
effectFn.deps = []
effectFn()
}嵌套的 effect 与 effect 栈
effect 是可以发生嵌套的,例如:
effect(function fn1 () {
effect(function fn2 () {
/*...*/
})
})什么情况下会出现嵌套的 effect 呢?实际上 Vue.js 的渲染函数就是在一个 effect 中执行的:
// Foo 组件
const Foo = {
render () {
return /*...*/
}
}在一个 effect 中执行 Foo 组件的渲染函数:
effect(() => {
Foo.render()
})当组件发生嵌套时,例如 Foo 组件渲染了 Bar 组件:
const Bar = {
render () {
return /*...*/
}
}
const Foo = {
render () {
return <Bar />
}
}此时就发生了 effect 嵌套,它相当于:
effect(() => {
Foo.render()
// 嵌套
effect(() => {
Bar.render()
})
})但观察现在的代码,我们用全局变量 activeEffect 来存储通过 effect 函数注册的副作用函数,这意味着同一时刻 activeEffect 所存储的副作用函数只能有一个。当副作用函数发生嵌套时,内层副作用函数的执行会覆盖 activeEffect 的值,并且永远不会恢复到原来的值。这时如果再有响应式数据进行依赖收集,即使这个响应式数据是在外层副作用函数中读取的,它们收集到的副作用函数也都会是内层副作用函数,这就是问题所在。
为了解决这个问题,我们需要一个副作用函数栈 effectStack,在副作用函数执行时,将当前副作用函数压入栈中,待副作用函数执行完毕后,将其从栈中弹出,并始终让 activeEffect 指向栈顶的副作用函数。这样就能做到一个响应式数据只会收集直接读取其值的副作用函数,而不会出现相互影响的情况。
如以下代码所示:
// 用一个全局变量存储当前激活的 effect 函数
let activeEffect
// effect 栈
const effectStack = [] // 新增
function effect (fn) {
const effectFn = () => {
cleanup(effectFn)
// 当调用 effect 注册副作用函数时,将副作用函数复制给 activeEffect
activeEffect = effectFn
// 在调用副作用函数之前将当前副作用函数压入栈中
effectStack.push(effectFn) // 新增
fn()
// 在当前副作用函数执行完毕后,将当前副作用函数弹出栈,并把 activeEffect 还原为之前的值
effectStack.pop() // 新增
activeEffect = effectStack[effectStack.length - 1] // 新增
}
// activeEffect.deps 用来存储所有与该副作用函数相关联的依赖集合
effectFn.deps = []
// 执行副作用函数
effectFn()
}这样,将内层副作用函数 effectFn2 执行完毕后,他会被弹出栈,并将副作用函数 effectFn1 设置为 activeEffect。这样一来,响应式数据就只会收集直接读取其值的副作用函数作为依赖,从而避免发生错乱。
避免无限递归循环
实现一个完善的响应式系统要考虑诸多细节,下面要介绍的无限递归循环就是其中之一。
举个例子:
const data = { foo: 1 }
const obj = new Proxy(data, { /*...*/ })
effect(() => obj.foo++)可以看到,在 effect 注册的副作用函数内有一个自增操作 obj.foo++,该操作会引起栈溢出:
Uncaught RangeError: Maximum call stack size exceeded
为什么会这样呢?
实际上,我们可以把 obj.foo++ 这个自增操作分开来看,它相当于 obj.foo = obj.foo + 1。在这个语句中,既会读取 obj.foo 的值,又会设置 obj.foo 的值,而这就是导致问题的根本原因。
首先读取 obj.foo 的值,这会触发 track 操作,将当前副作用函数收集到 “桶” 中,接着将其加 1 后再赋值给 obj.foo,此时又会同时触发 trigger 操作,即把 “桶” 中的副作用函数取出并执行。此时又会触发相同的操作,会无限递归的调用自己,于是就产生了栈溢出。
通过分析,我们发现读取和设置操作是在同一个副作用函数内进行的,此时无论是 track 时收集的副作用函数,还是 trigger 时要触发执行的副作用函数,都是 activeEffect。基于此,我们可以在 trigger 动作发生时增加守卫条件:如果 trigger 触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行,如下代码所示:
function trigger (target, key) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
const effectsToRun = new Set()
effects && effects.forEach(effectFn => {
// 如果 trigger 触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行
if (effectFn !== activeEffect) { // 新增
effectsToRun.add(effectFn)
}
})
effectsToRun.forEach(effectFn => effectFn())
}这样我们就能避免无限递归调用,从而避免栈溢出。
调度执行
可调度性:当 trigger 动作触发副作用函数重新执行时,有能力决定副作用函数执行的时机、次数以及方式
可调度性也是响应系统非常重要的特性