Consider only calculating loss over patches #3
Description
One note from Context Encoders: Feature Learning by Inpainting is that they only compute loss over the patch.
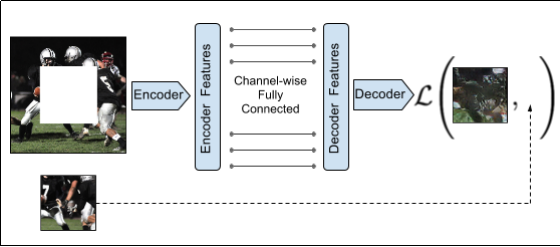
We should probably consider this approach. Is it better than ours? Are we getting noise from computing loss over the entire image or do they not contribute to the gradients and not matter? Is performance notably improved by calculating loss only over patches?